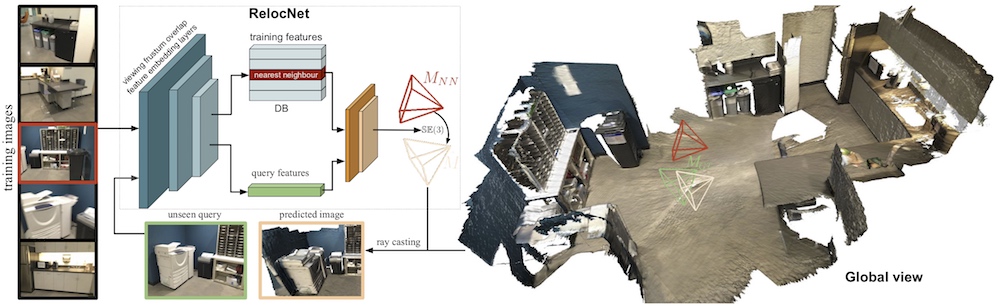
RelocNet is a method of learning suitable convolutional representations for camera pose retrieval based on nearest neighbour matching and continuous metric learning-based feature descriptors. We introduce information from camera frusta overlaps between pairs of images to optimise our feature embedding network. Thus, the final camera pose descriptor differences represent camera pose changes. In addition, we build a pose regressor that is trained with a geometric loss to infer finer relative poses between a query and nearest neighbour images.
RelocDB is our relocalisation dataset, comprising of 500 sequences filmed on a Google Tango-equipped mobile phone. Each sequence captures a single room twice, and provides 30 fps RGB data, 5 fps depth data, along with intrinsic camera calibration, timestamps and poses for data streams.
If you use our method or our dataset, please cite our ECCV 2018 paper:
@InProceedings{Balntas_2018_ECCV,
author = {Balntas, Vassileios and Li, Shuda and Prisacariu, Victor Adrian},
title = {RelocNet: Continuous Metric Learning Relocalisation using Neural Nets},
booktitle = {The European Conference on Computer Vision (ECCV)},
month = {September},
year = {2018}
}
RelocNet
Links: Paper Presentation Poster
The code is part of AVLCode and is available on GitHub.
RelocDB
Out dataset will be available very soon. Please sign up below to be notified when it becomes available:
We provide a description for our dataset here and tutorials showing how the data can be read in C++ and Python can be found here.